Organizations deploying GPU infrastructure for AI training and inference are also taking on a new class of network challenge. AI workloads generate traffic patterns that differ fundamentally from traditional enterprise applications: massive data ingestion flows before training runs, high-bandwidth model checkpointing to distributed storage, sustained inference traffic from thousands of concurrent users, and management traffic that spans the cluster boundary continuously.
For network and security teams, the question is not whether this traffic is visible: it flows over standard IP networks and generates NetFlow records on the switches and routers at the cluster boundary. The question is whether anyone is monitoring it, baselining it, and watching for the anomalies that indicate performance problems or security incidents.
This blog covers where NetFlow Optimizer (NFO) provides specific, defensible value for teams managing AI infrastructure networks, and is honest about where it does not.
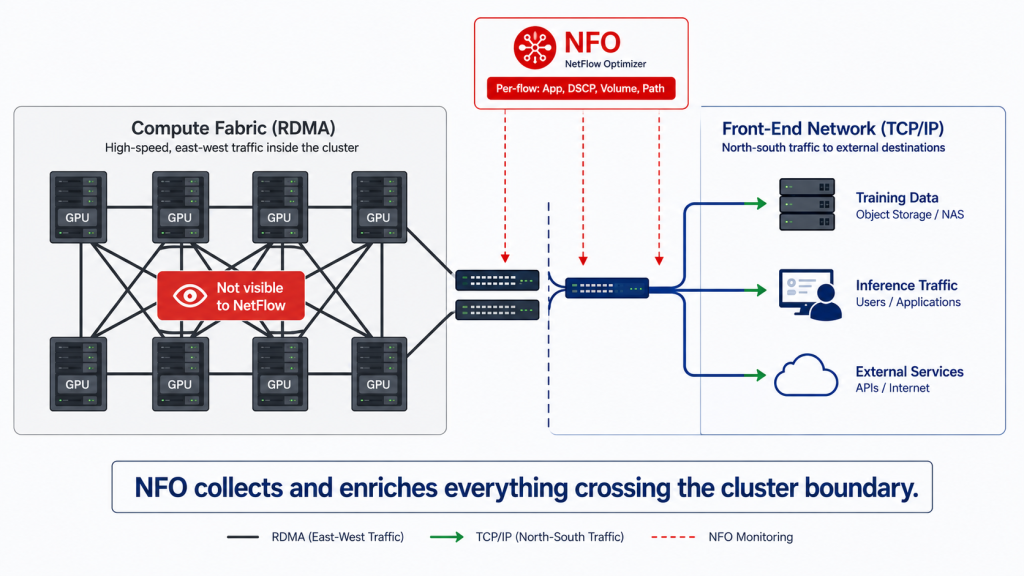
What NetFlow Sees in an AI Cluster Network
AI cluster networks have two distinct traffic planes. Understanding which one NetFlow covers is essential before drawing conclusions about visibility.
The East-West Compute Fabric: Not Visible
GPU-to-GPU communication during model training runs over a dedicated compute fabric. In 2026, RoCEv2 over Ethernet has emerged as the dominant technology for enterprise AI clusters, with InfiniBand remaining dominant for the largest hyperscale deployments. Both are RDMA technologies. RDMA traffic bypasses the IP stack and is not visible to NetFlow or sFlow collection regardless of whether the underlying physical layer is InfiniBand or Ethernet.
This is an important boundary to be clear about: NFO does not see east-west GPU training traffic in the vast majority of enterprise AI deployments. Dedicated RDMA monitoring tools are required for compute fabric visibility.
The North-South Front-End Network: Fully Visible
Every AI cluster connects to the broader enterprise network through a standard IP front-end network. This carries data ingestion from storage and data lakes, model checkpointing, inference serving to users and downstream applications, and cluster management and orchestration traffic. All of it runs over standard TCP/IP and generates NetFlow records on the boundary switches and routers.
NFO does not see inside the GPU compute fabric. It provides full visibility into everything that crosses the cluster boundary: data flows in and out, inference traffic, management connections, and any unauthorized external communications.
Three Use Cases Where NFO Adds Specific Value
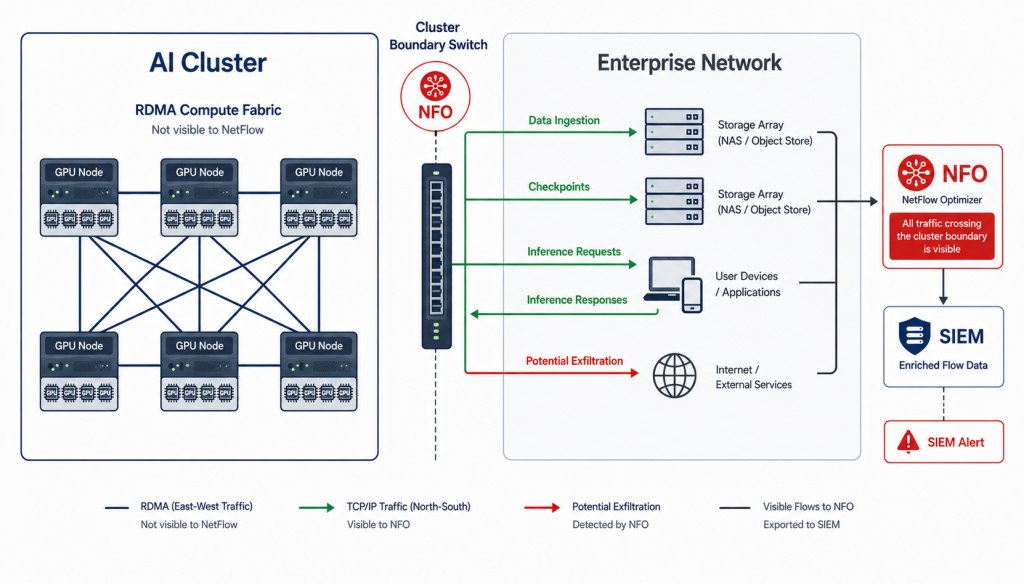
1. Data Ingestion and Storage Traffic Monitoring
AI training workloads require massive data ingestion: datasets moved from object storage, data lakes, or NFS storage to GPU nodes before and during training runs. These transfers generate sustained high-bandwidth flows between storage systems and the cluster that are fully visible in NetFlow records from the boundary switches.
NFO’s per-flow, per-application bandwidth data shows which storage endpoints are serving which GPU nodes, at what volume, and at what times. For capacity planning this is directly useful: identifying whether storage network saturation is contributing to training job slowdowns, which storage tiers are most heavily utilized, and whether data preprocessing pipelines are generating unexpected traffic that competes with training workloads for network bandwidth.
2. Inference Traffic Baselining and Anomaly Detection
Inference workloads generate a distinct traffic pattern from training: many concurrent requests from users or downstream services to GPU nodes serving model responses. AI clusters are increasingly hybrid, with dedicated RDMA fabrics for training and standard Ethernet for inference serving. The inference side is fully visible in NetFlow data.
NFO enriches inference traffic records with application context, GeoIP data, and, where applicable, user identity from Active Directory, Entra ID, Okta, and VPN authentication logs, and delivers this stream to your SIEM or monitoring platform. This enriched data makes it possible for upstream systems to baseline normal inference traffic patterns and detect deviations: unexpected spikes in request volume, connections from unauthorized source IPs, inference endpoints accessed outside normal operational windows, or unusual geographic origins for API calls. For organizations running AI services in regulated environments, this visibility supports the continuous network monitoring and audit trail requirements of applicable compliance frameworks.
3. AI Infrastructure Security Monitoring
AI infrastructure represents a high-value target. Trained model weights, proprietary training datasets, and the computational resources themselves are all attractive to adversaries. NFO delivers enriched flow telemetry at the cluster boundary that gives upstream security systems the data they need to identify three specific threat categories:
- Model and dataset exfiltration: Large outbound transfers from storage systems or cluster nodes to unexpected external destinations are the primary indicator. Flow duration and cumulative volume analysis over extended windows applies directly to AI asset exfiltration. See Defeating the Low and Slow for the full detection methodology.
- Unauthorized access to inference endpoints: First-contact connections from source IPs not in the authorized access list for AI services appear immediately in NFO’s flow telemetry, enriched with GeoIP and threat intelligence context.
- Supply chain compromise indicators: Unexpected outbound connections from AI infrastructure to external destinations during or after model deployment (package repositories, unknown endpoints, or destinations flagged by threat intelligence) are visible in north-south flow data and warrant investigation.
NFO Visibility Summary for AI Infrastructure
| Traffic Type | NFO Visibility | Value Delivered |
| Data ingestion from storage to GPU nodes | Full | Bandwidth monitoring, storage capacity planning, training bottleneck identification |
| Model checkpointing to distributed storage | Full | Checkpoint frequency and volume tracking, storage utilization visibility |
| Inference serving (users and applications to GPU nodes) | Full | Enriched data foundation for upstream baselining, anomaly detection, unauthorized access detection, and audit trail for regulated environments |
| Management and orchestration traffic | Full | Unexpected management connections, configuration change indicators, first-contact external destinations |
| Outbound connections from AI infrastructure (potential exfiltration) | Full | Enriched outbound flow data enabling exfiltration detection, supply chain compromise identification, and threat intelligence screening in upstream security systems |
| East-west GPU training traffic (RoCEv2 or InfiniBand compute fabric) | Not visible | RDMA bypasses the IP stack; dedicated RDMA monitoring tools required for compute fabric visibility |
Deploying NFO for AI Infrastructure Visibility
NFO is software-only and deploys on standard Linux or Windows Server with no hardware changes to AI infrastructure. The deployment model is straightforward: NFO collects NetFlow or IPFIX from the boundary switches and routers connecting the AI cluster to the storage network and enterprise network, enriches the data, and delivers it to your SIEM or monitoring platform in under one hour.
For organizations delivering AI services in regulated environments, NFO’s on-premises, air-gap-compatible architecture ensures that AI infrastructure telemetry stays inside the security boundary. See the NFO Government Solution Brief for deployment architecture details relevant to classified and sensitive environments.
The Bottom Line
NFO does not provide visibility into the GPU compute fabric. That requires dedicated RDMA monitoring tools. What it provides is continuous, enriched network telemetry for everything that crosses the AI cluster boundary: the storage traffic that feeds training runs, the inference traffic that serves users, the management traffic that operates the cluster, and the outbound connections that could indicate a security incident.
For most enterprises deploying AI infrastructure, the cluster boundary is where the security and operational visibility gaps are largest and least addressed. The RDMA fabric has specialized monitoring tooling built around it. The front-end network is frequently less instrumented.
The GPU cluster is the new crown jewel of enterprise infrastructure. The network around it deserves the same visibility as any other critical asset.
Want to add network visibility to your AI infrastructure environment? Start a free 60-day trial of NetFlow Optimizer or schedule a technical demo.
Start Free Trial | Schedule a Demo | Government Solution Brief | NFO Documentation