When an application slows down or a network segment becomes sluggish, the clock starts ticking. For Incident Response (IR) teams, the first few minutes are defined by a single, critical question: Is this a security event or a hardware failure?
Answering this question traditionally requires “swivel-chairing” between two disconnected worlds:
- NetFlow/IPFIX: Which tells you what the traffic is doing.
- SNMP: Which tells you how the hardware is holding up.
Without correlation, these are just two separate piles of data. The NetFlow Optimizer (NFO) bridges this gap by unifying these two pillars into a single, enriched data stream, allowing analysts to perform instant root cause analysis.
The Blind Spots of Single-Pillar Monitoring
Monitoring either traffic or hardware in isolation leads to high Mean Time to Identification (MTTI):
- Flow-Only Monitoring: You see a massive traffic spike from a specific database server. Is it a data exfiltration attempt (security)? Or is it a legitimate backup process that started early (operations)?
- SNMP-Only Monitoring: You see a core switch’s CPU hitting 98%. Is the hardware overheating (thermal throttling)? Or is it being overwhelmed by a high volume traffic with CPU intensive tasks like deep packet inspection (DPI), or Distributed Denial of Service (DDoS) attack?
In both scenarios, the analyst must manually hunt for the “missing half” of the story. By the time the data is correlated, the damage—whether it’s downtime or data loss—is already done.
The Technical Deep Dive: NFO Correlation in Action
NFO’s dual ingestion engine processes NetFlow and SNMP health metrics simultaneously, delivering a unified, enriched record to your IT Operations or SIEM platform (such as Splunk ITSI). This eliminates the “data silo” problem during a crisis.
The Scenario: The “Friday Afternoon Slump”
Imagine your monitoring system alerts you to extreme latency on a critical payroll application.
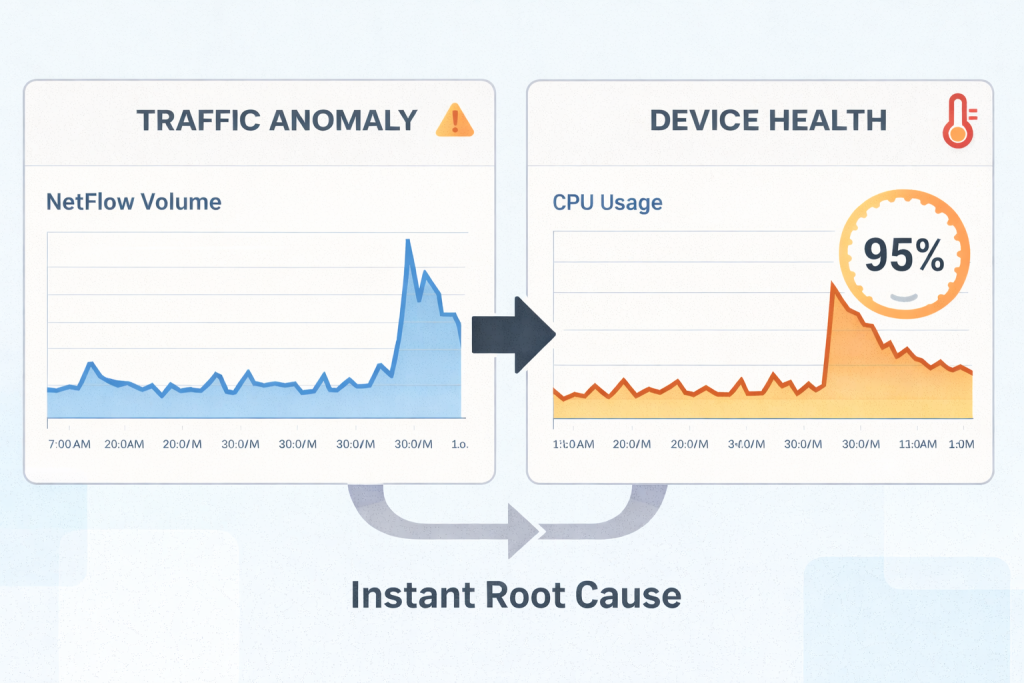
- Pillar 1: The Traffic Anomaly (NetFlow)
NFO reports a massive spike in flow records on the core distribution switch. Rather than just seeing “Port 443” traffic, NFO delivers the Application Name (as identified by the network device’s DPI) and correlates it with User Identities. The analyst sees that users in the “Marketing” group are currently pushing massive data volumes via a cloud-based video editing suite.
- Pillar 2: The Hardware Context (SNMP)
Simultaneously, NFO’s SNMP engine is polling the switch’s health. It reports that the CPU usage has spiked to 95% and Backplane Utilization is nearing its ceiling.
- The Unified Conclusion (MTTR in Seconds)
Because NFO provides a unified output, the analyst sees the Traffic Spike, the Application Identity, and the CPU Exhaustion on a single timeline.
- The Diagnosis: The hardware isn’t failing, and it isn’t a security breach. The device is simply being overwhelmed by legitimate, high-bandwidth application traffic from a specific department.
- The Result: Instead of a four-hour “war room” investigation to rule out a DDoS attack or a hardware defect, the issue is identified in under two minutes. The solution is clear: apply a Rate Limit or Quality of Service (QoS) policy to that specific application.
Why Dual Ingestion is Essential for MTTR
By linking the “what” (NetFlow) with the “how” (SNMP), NFO provides three distinct advantages:
- Differentiating Attacks from Failures: Instantly distinguish between a DDoS attack (High Flow + High CPU) and a hardware malfunction like a “broadcast storm” caused by a failing loop-prevention protocol.
- Validating Capacity Planning: Identify when a device is consistently reaching its hardware limits during peak traffic hours, providing the data needed for justified hardware upgrades.
- Optimizing SIEM Correlation: Instead of flooding your SIEM with millions of raw flows with naked IP addresses and basic status polls, NFO sends high-fidelity, pre-processed events. By enriching flows with identity and reporting only the relevant, vendor-specific SNMP metrics, NFO ensures that when these two streams meet in your SIEM, they correlate instantly. This reduces the processing load on your SIEM, lowers storage costs, and eliminates the “alert fatigue” caused by trying to manually link disconnected data points.
Conclusion: Two Pillars, One Vision
Effective Incident Response requires more than just data; it requires contextual intelligence.
By treating NetFlow and SNMP as two halves of the same whole, the NetFlow Optimizer provides the visibility needed to stop the “guessing game.” Whether you are facing a sophisticated security threat or a simple hardware bottleneck, the ability to correlate traffic with device health is the only way to drive your MTTR toward zero.
Is your team still swivel-chairing between flow and health data?
Contact us today to learn how NFO’s dual ingestion can transform your Incident Response, or Schedule a Demo to see this correlation in action within your own environment.