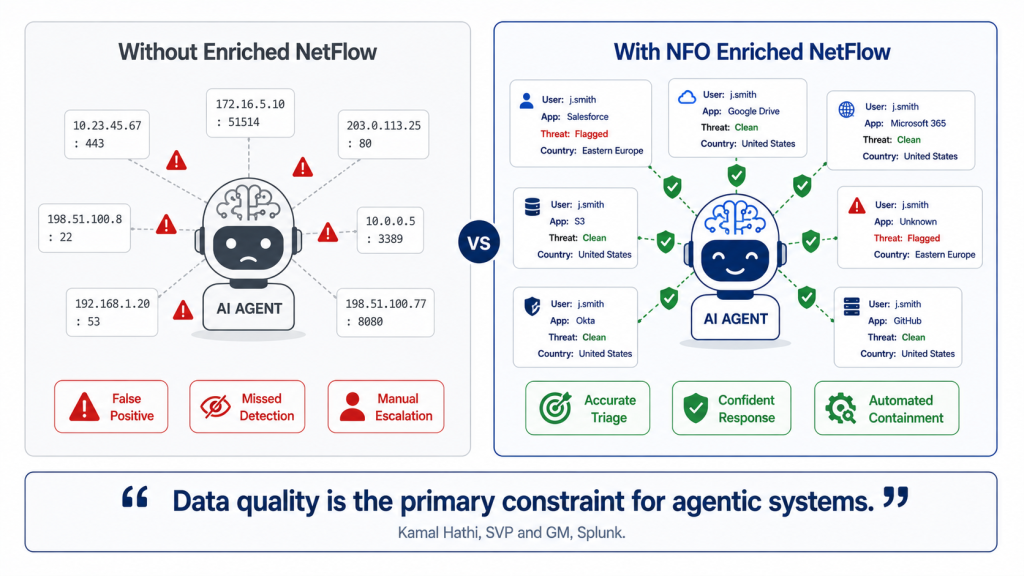
“Data quality is a primary constraint for agentic systems.”
That statement, delivered by Splunk’s own GM at Cisco Live Las Vegas 2026, cuts to the core architectural challenge of the Agentic SOC. The vision is compelling: AI agents that autonomously triage alerts, investigate threats, contain incidents, and remediate damage across the full security lifecycle without waiting for human analysts. Cisco Live 2026 centered on this shift from chatbots to agentic AI, with agents positioned as digital coworkers now deployed across data centers, campuses, and branches.
But an AI agent that makes autonomous decisions based on incomplete or low-quality data is not a force multiplier for your SOC. It is a liability. And for most organizations deploying agentic security tools today, the data quality gap is most acute in one specific telemetry category: network flow data.
This blog explains why network flow telemetry is the data layer most likely to constrain Agentic SOC effectiveness, and how NetFlow Optimizer (NFO) addresses that constraint by delivering enriched, normalized, high-fidelity network telemetry into Splunk before agentic workflows begin.
The Agentic SOC Data Foundation
At Cisco Live 2026, Splunk announced that the Cisco Data Fabric is designed to become the system of record and intelligence layer for the agentic enterprise, consolidating telemetry across network, application, security, and third-party sources into a common layer that both human analysts and automated agents draw from.
New tools like Agent Builder and AI Canvas let security and IT teams build custom AI agents and investigate issues using natural language, shifting operations from reactive to predictive. The promise is that these agents can triage, investigate, and respond faster and more accurately than human analysts working alone.
The premise holds, but only if the data foundation is solid. Agentic systems make automated decisions and take automated actions. A false positive from an AI agent that blocks a legitimate user, isolates a healthy system, or fires an alert cascade is harder to recover from than one that lands in a human analyst’s queue. The data quality constraint Kamal Hathi identified is not a detail. It is the core architectural challenge.
For most Splunk deployments, the weakest link in that data foundation is network telemetry.
Why Network Telemetry Is the Weakest Link
Endpoint logs, authentication events, and cloud audit trails are well-understood data sources with mature ingestion pipelines and established Splunk content. Network flow telemetry is different. As we covered in detail in The NetFlow Volume Problem, raw NetFlow is binary, Splunk cannot ingest it directly, and most organizations either have no NetFlow in Splunk at all or have a degraded, context-free version that arrived through a basic collector.
For human analysts, context-free network telemetry is an inconvenience. An alert fires, an analyst pivots to a lookup table to resolve an IP to a user, checks a threat feed to confirm a destination’s reputation, and manually assembles the picture. Slow, but manageable.
For an AI agent, context-free telemetry is a structural problem. Agentic decision-making depends on data that is complete, consistent, and carries sufficient context for the agent to make a confident decision without manual enrichment steps. An agent operating on flow records that show only source IP, destination IP, and byte counts is working with less than half the information it needs. The result is one of two failure modes:
- False positives: The agent treats an unrecognized IP or an unfamiliar flow pattern as suspicious, fires an alert or takes a containment action, and turns out to have targeted a legitimate business application running from a new server. The IP was unknown because the enrichment data was not there, not because the traffic was malicious.
- False negatives: A genuine threat actor using a known application protocol over a whitelisted port generates traffic that looks, to a context-free agent, indistinguishable from legitimate traffic. Without user identity, application context, or behavioral deviation from baseline, the agent has no signal to act on.
Both failure modes erode trust in the agentic system and push analysts back toward manual investigation. That is exactly the outcome the Agentic SOC is designed to eliminate.
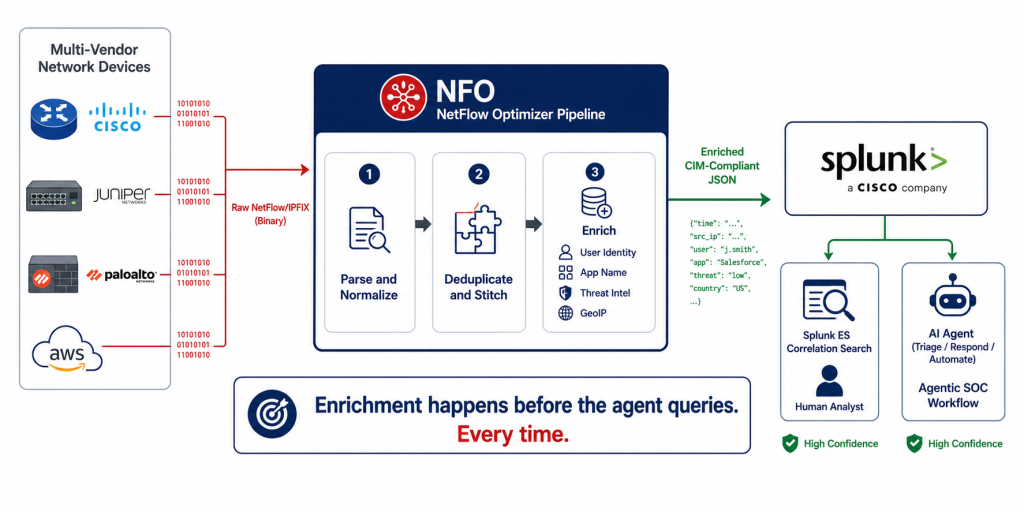
What Enriched Network Telemetry Gives Agentic Workflows
NFO delivers enriched, normalized network flow telemetry into Splunk before agentic workflows begin. It is a pipeline product: it receives raw NetFlow and IPFIX from your existing network infrastructure, applies enrichment and volume reduction, and outputs structured, CIM-compliant data to Splunk via HEC. The enrichment happens inside NFO before any record reaches the Splunk index, so every flow that an AI agent queries already carries the context it needs.
The specific enrichment fields that matter most for agentic security decision-making:
| Enrichment Field | What Raw NetFlow Shows | What NFO Adds |
| User identity | Source IP: 10.1.4.22 | User: j.smith@company.com (resolved from AD/Entra ID/Okta in real time) |
| Application name | Port: 443 | Application: Salesforce (resolved via device DPI or NFO application catalog) |
| Threat intelligence | Destination IP: 198.51.100.45 | Threat score: flagged / Category: C2 infrastructure / Reputation: malicious |
| GeoIP and ASN | Destination IP: 203.0.113.8 | Country: IR (Iran) / ASN: AS209588 (Flyservers S.A.) |
| Bidirectional flow context | Two separate ingress and egress records requiring join | Single stitched record with full byte counts, duration, and direction |
With these fields pre-indexed in Splunk, an AI agent investigating a suspicious outbound connection has immediate access to: the named user behind the source IP, the application generating the traffic, the reputation of the destination, the geographic context, and the complete bidirectional conversation. It can make a high-confidence triage decision in a single query pass rather than executing three to five sequential enrichment API calls.
The Multi-Vendor Coverage Gap
Cisco’s Nexus One platform delivers native Splunk integration for Cisco data center fabric telemetry, streaming anomalies, advisories, and audit logs from Cisco Nexus switches directly to Splunk. This is a meaningful capability for organizations running Cisco data center infrastructure.
It is, however, Cisco infrastructure only. Enterprise and government networks are not homogeneous. A typical large organization runs Juniper, Aruba, Palo Alto, Fortinet, and Cisco devices simultaneously. Branch networks mix vendors. Government environments often span multiple generations of equipment across agencies and contractors. The network telemetry that Nexus One delivers to Splunk covers Cisco fabric devices. It does not cover the rest of the network.
NFO ingests NetFlow and IPFIX from all of them: Cisco, Juniper, Aruba, Palo Alto, Fortinet, and any other device that exports flow data, alongside cloud VPC flow logs from AWS, Azure, GCP, and Oracle OCI. It normalizes all of those disparate formats into a single consistent stream in Splunk. For an Agentic SOC that needs to reason across the full network, that multi-vendor, unified telemetry layer is the foundation that Nexus One alone cannot provide. The two are complementary: Nexus One covers Cisco fabric depth; NFO covers multi-vendor breadth.
Volume and Noise: The Other Data Quality Constraint
Data quality for agentic systems is not only about enrichment. It is also about signal-to-noise ratio. An AI agent operating on redundant, duplicated, or structurally noisy data will generate more false positives, require more compute to process, and produce less reliable confidence scores than an agent operating on a clean, deduplicated stream.
Raw NetFlow from a large enterprise network suffers from well-documented structural redundancy: the same conversation reported independently by multiple switches it crosses, ingress and egress records that are separate halves of the same bidirectional flow. NFO’s aggregation, deduplication, and flow-stitching pipeline removes this redundancy before the data reaches Splunk, typically reducing total volume by 80 to 90 percent without losing any security-relevant conversation. For the Agentic SOC, this volume reduction has a direct operational benefit: the agent’s search and correlation workload is reduced, its results are cleaner, and its confidence thresholds are more reliable because the underlying data has fewer duplicate signals inflating pattern counts.
For a full breakdown of how NFO’s volume reduction works and why it does not sacrifice fidelity, see The NetFlow Volume Problem: How NFO Makes Network Telemetry Viable in Splunk.
The Bottom Line
Splunk’s Kamal Hathi said it directly at Cisco Live Las Vegas 2026: data quality is the primary constraint for agentic systems. For network telemetry specifically, that constraint has two dimensions: the data must be rich enough for an agent to make confident decisions (enrichment), and clean enough for those decisions to be accurate (volume and noise reduction).
Raw NetFlow satisfies neither condition. It cannot reach Splunk in its binary form, and even when it arrives via a basic collector, it carries IP addresses and byte counts where agents need user identities, application names, and threat intelligence scores.
NFO is the pipeline that bridges that gap: enriched, normalized, deduplicated network telemetry, delivered into Splunk before agentic workflows begin. The Agentic SOC is only as good as the data it acts on. NFO makes network telemetry data worth acting on.
Ready to give your Agentic SOC the network telemetry foundation it needs? Start a free 60-day trial of NetFlow Optimizer or schedule a technical demo with a NetFlow Logic engineer.
Start Free Trial | Schedule a Demo | Splunk Integration | NFO Documentation